Análisis de Red de Co-ocorrencia de Terminos
Este script de Python utiliza las bibliotecas Pandas, NetworkX y Matplotlib para construir, analizar y visualizar una red de coocurrencia de términos a partir de un archivo de texto. El proceso incluye el preprocesamiento del texto en español, el cálculo de métricas de red (PageRank, clústeres) y un flujo interactivo para corregir la acentuación antes de generar el gráfico final.
Galería de Gráficos
Diferentes visualizaciones generadas por el script, mostrando layouts alternativos (Circular vs. Kamada-Kawai) y estilos de color (Monocromático vs. Clusters).
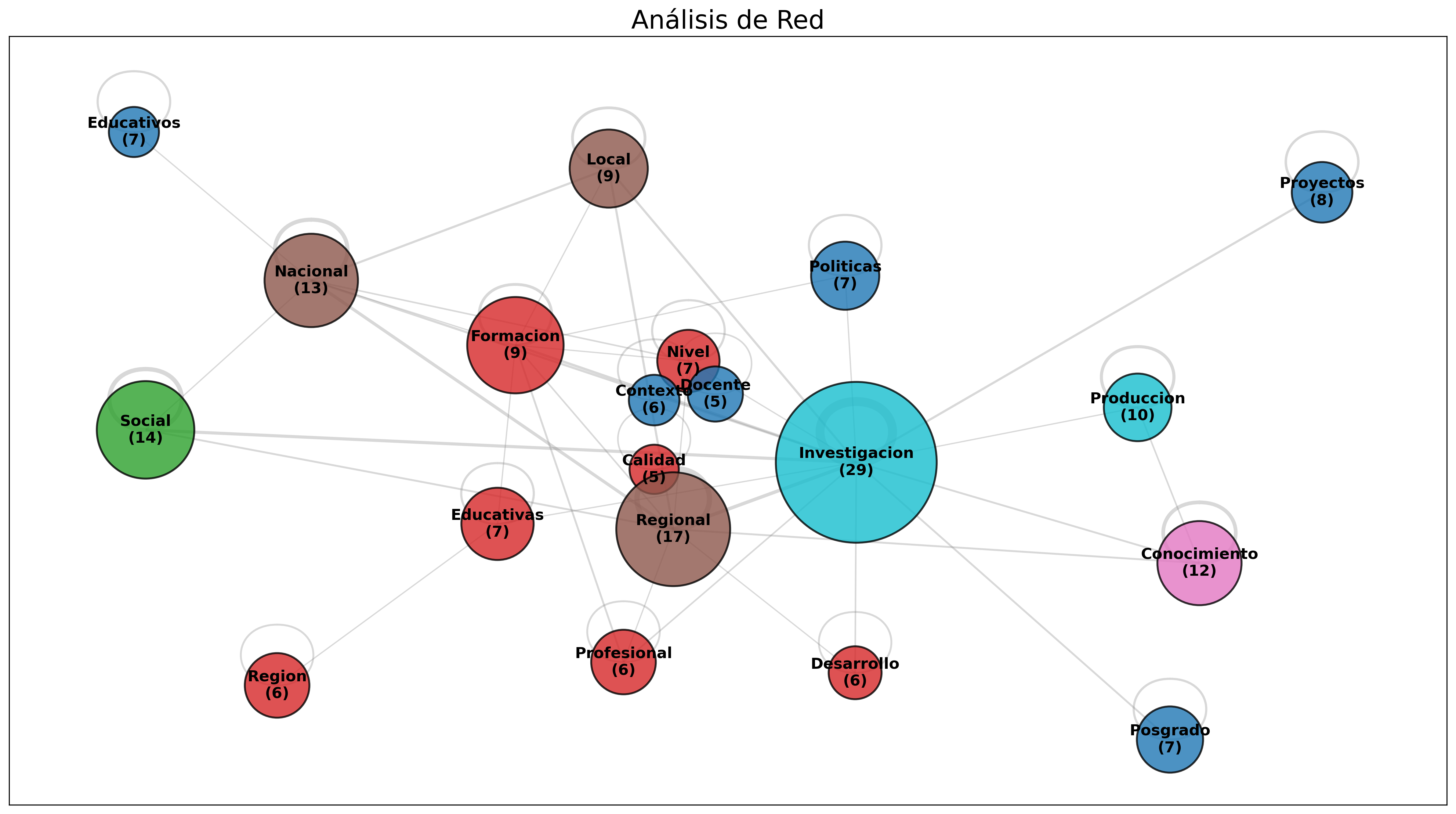
Colorido por Clusters (Layout Kamada)
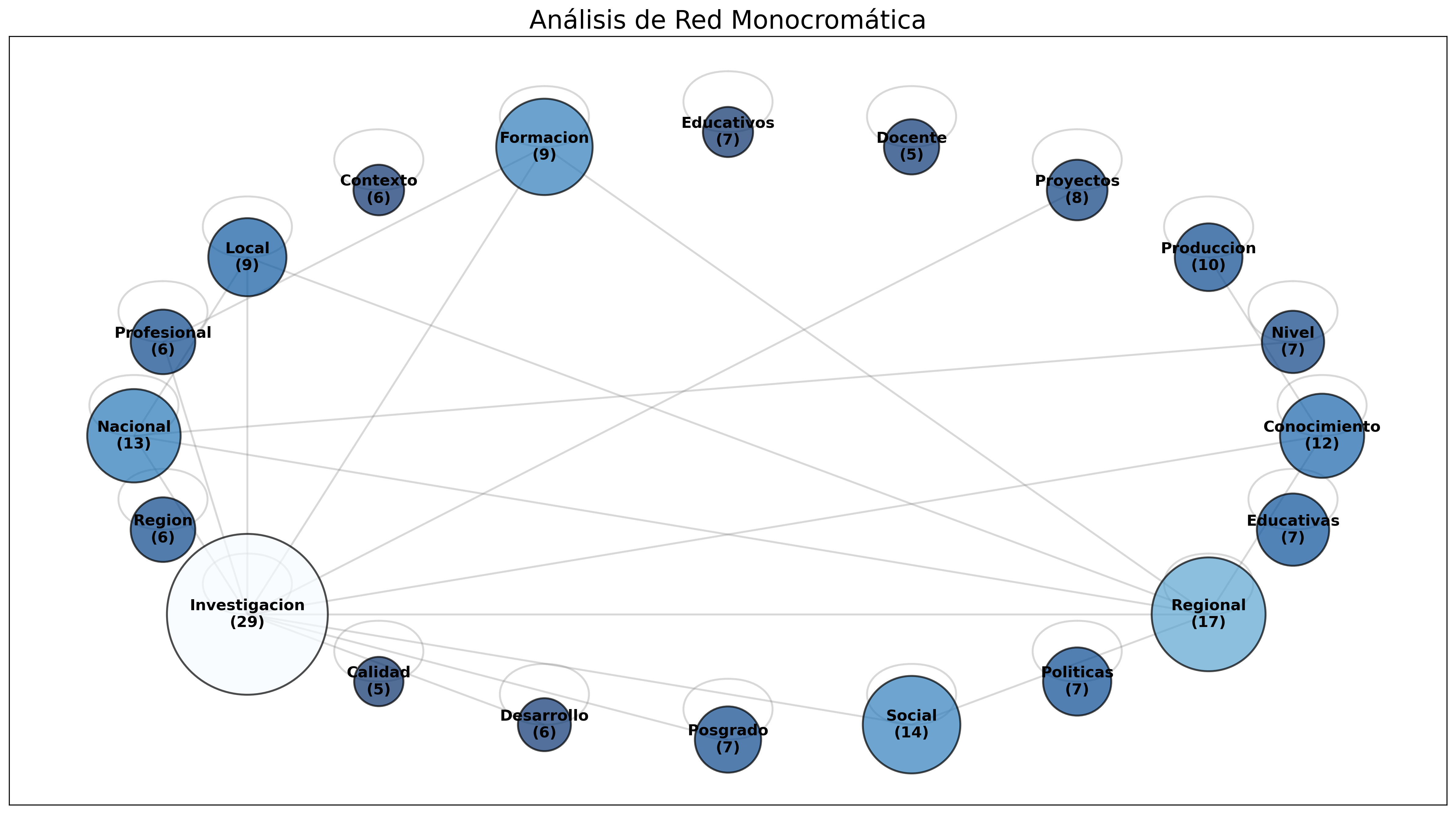
Monocromático (Layout Circular)
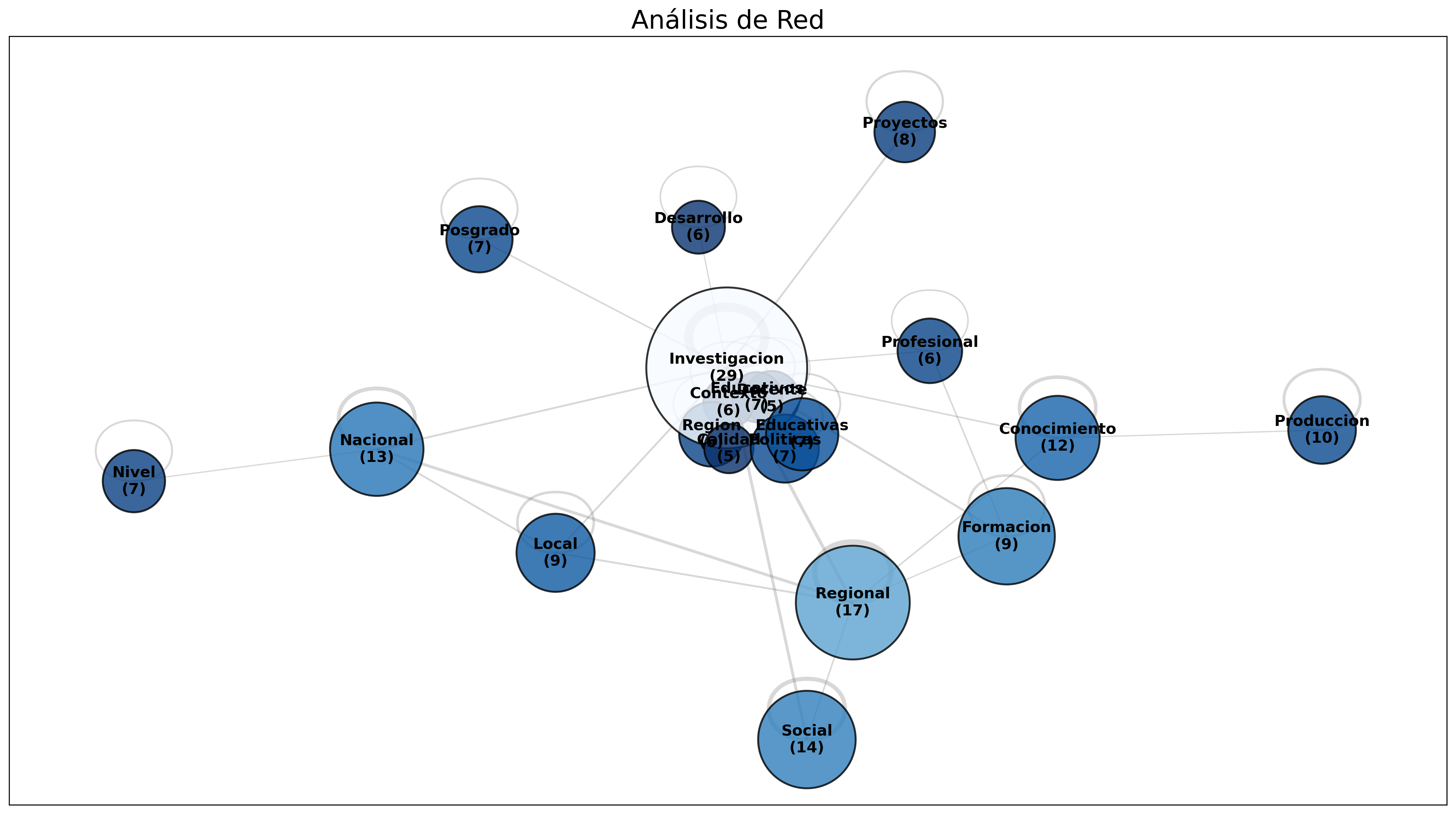
Monocromático (Layout Kamada)
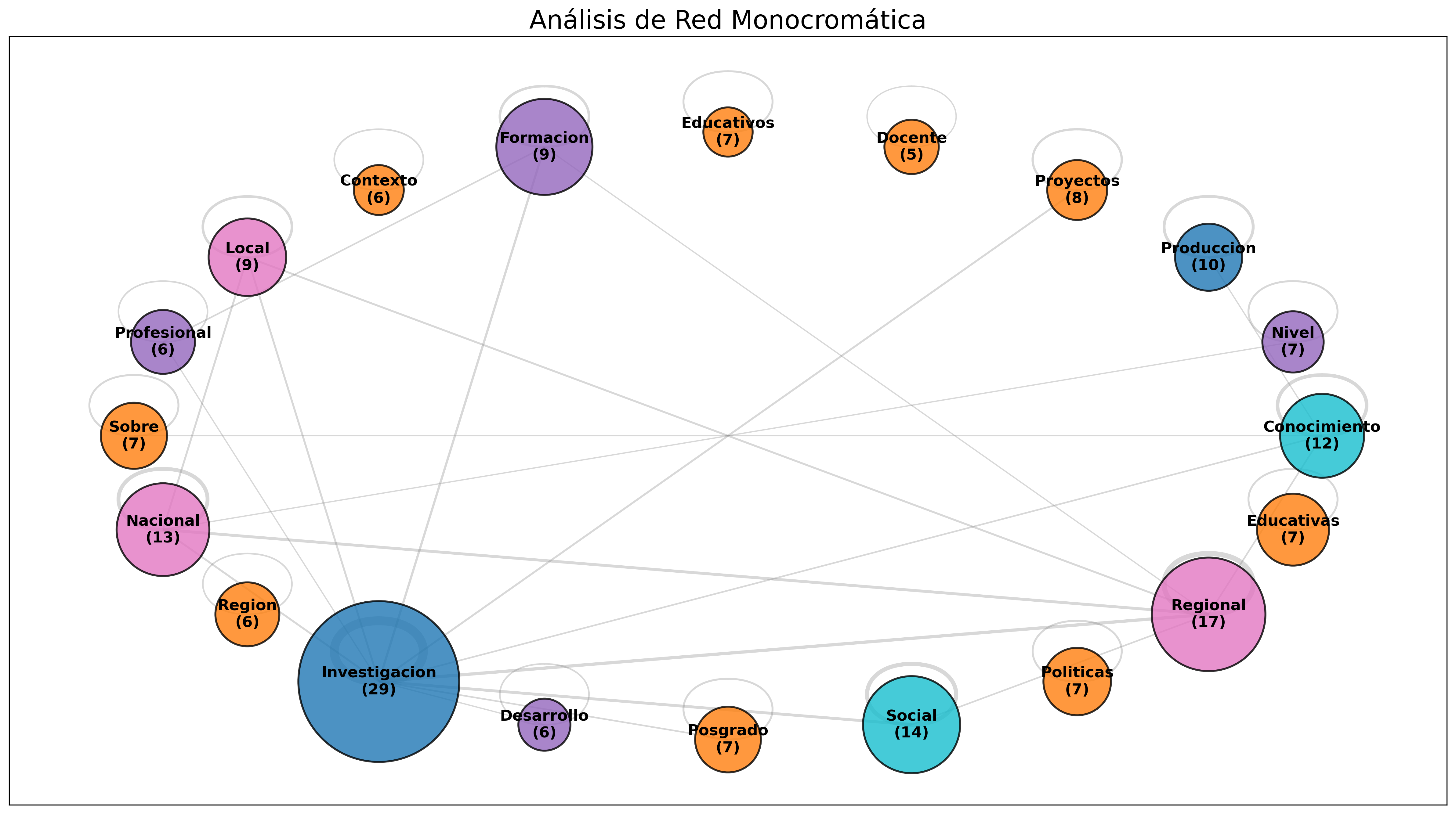
Layout Kamada (Estilo alternativo)
Visita el Repositorio del Proyecto
Para descargar el script completo, ver la documentación `README.md` y explorar el código fuente, visita el repositorio oficial en GitHub.
Ir a GitHub →Script Python Completo
import pandas as pd
import networkx as nx
import re
from itertools import combinations
import community as community_louvain
import matplotlib.pyplot as plt
import unicodedata # Para eliminar tildes
import numpy as np # Para normalizar
# --- Función para eliminar tildes ---
def _eliminar_tildes(texto):
nfkd_form = unicodedata.normalize('NFD', texto)
return "".join([c for c in nfkd_form if unicodedata.category(c) != 'Mn'])
# --- Función de Preprocesamiento (Español) ---
def preprocess_text(text, custom_stopwords=None):
mapa_normalizacao = {
'investigaciones': 'investigacion',
'docentes': 'docente',
'estudiantes': 'estudiante',
'sociales': 'social',
'educacionales': 'educacional',
'nacionales': 'nacional',
'regionales': 'regional',
'locales': 'local',
'institucionales': 'institucional',
'profesionales': 'profesional',
'populares': 'popular',
'municipales': 'municipal',
'politicas': 'politica', # 'políticas' se vuelve 'politica'
'acciones': 'accion', # 'acción' se vuelve 'accion'
'redes': 'red',
'universidades': 'universidad'
}
stop_words = set(['de', 'a', 'o', 'que', 'y', 'e', 'el', 'la', 'en', 'un', 'una', 'para',
'con', 'no', 'los', 'las', 'por', 'mas', 'más', 'se', 'su', 'sus',
'como', 'pero', 'al', 'del', 'le', 'lo', 'me', 'mi', 'sin', 'son',
'tambien', 'también', 'este', 'esta', 'estos', 'estas', 'ser', 'es'])
if custom_stopwords:
# Normalizar también las stopwords personalizadas
normalized_custom = [_eliminar_tildes(sw.lower()) for sw in custom_stopwords]
stop_words.update(normalized_custom)
text = text.lower()
text = _eliminar_tildes(text) # <-- PASO CLAVE
text = re.sub(r'[^\w\s]', '', text)
text = re.sub(r'\d+', '', text)
tokens = text.split()
normalized_tokens = [mapa_normalizacao.get(token, token) for token in tokens]
filtered_tokens = [word for word in normalized_tokens if word not in stop_words and len(word) > 2]
return filtered_tokens
# --- Función de Creación de Matriz ---
def create_cooccurrence_matrix_from_file(filepath):
with open(filepath, 'r', encoding='utf-8') as file:
content = file.read()
documents_raw = content.split('###')
documents_raw = [doc.strip() for doc in documents_raw if doc.strip()]
# Esta lista ahora se pasa desde el bloque principal, pero la dejamos aquí como ejemplo
# custom_stopwords = ['programa', 'educacion', 'pdi', 'art', 'articulo']
# Pasamos una lista vacía de stopwords personalizadas, ya que se definen en el bloque principal
processed_docs = [preprocess_text(doc, []) for doc in documents_raw]
vocabulary = sorted(list(set(term for doc in processed_docs for term in doc)))
M = pd.DataFrame(0, index=vocabulary, columns=vocabulary, dtype=int)
for doc in processed_docs:
unique_terms_in_doc = sorted(list(set(doc)))
for term in unique_terms_in_doc:
M.loc[term, term] += 1
for term1, term2 in combinations(unique_terms_in_doc, 2):
M.loc[term1, term2] += 1
M.loc[term2, term1] += 1
return M
# --- Función de Métricas ---
def calcular_e_associar_metricas(G, M):
partition = community_louvain.best_partition(G, weight='weight')
pagerank = nx.pagerank(G, weight='weight')
occurrences = {term: M.loc[term, term] for term in G.nodes()}
clusters_ajustados = {node: cluster_id + 1 for node, cluster_id in partition.items()}
nx.set_node_attributes(G, clusters_ajustados, 'cluster')
nx.set_node_attributes(G, pagerank, 'pagerank')
nx.set_node_attributes(G, occurrences, 'occurrences')
print("Métricas (Cluster, PageRank, Ocorrencias) calculadas y asociadas a los nodos.")
return G
# --- Función de Filtrado ---
def filtrar_rede(G, top_n, min_edge_weight_for_viz):
if G.number_of_nodes() <= top_n: # <-- HTML escape para <
top_nodes = list(G.nodes())
else:
pagerank_dict = nx.get_node_attributes(G, 'pagerank')
sorted_nodes = sorted(pagerank_dict, key=pagerank_dict.get, reverse=True)
top_nodes = sorted_nodes[:top_n]
G_sub = G.subgraph(top_nodes).copy()
G_final = nx.Graph()
G_final.add_nodes_from(G_sub.nodes(data=True))
for u, v, data in G_sub.edges(data=True):
if data['weight'] >= min_edge_weight_for_viz: # <-- HTML escape para >
G_final.add_edge(u, v, weight=data['weight'])
G_final.remove_nodes_from(list(nx.isolates(G_final)))
print(f"Red final (Top {top_n} nodos, Bordes >= {min_edge_weight_for_viz}): {G_final.number_of_nodes()} nodos, {G_final.number_of_edges()} bordes.")
return G_final
# --- Función de Visualización (Monocromática) ---
def visualizar_rede(G, title, output_filename):
if G.number_of_nodes() == 0:
print("La red está vacía. No es posible generar el gráfico.")
return
plt.figure(figsize=(16, 9))
pos = nx.kamada_kawai_layout(G)
pagerank_values = [data.get('pagerank', 0) for _, data in G.nodes(data=True)]
# Lógica de Tamaño
min_size = 1500
max_size = 16000
node_sizes = []
if pagerank_values:
min_pr = min(pagerank_values)
max_pr = max(pagerank_values)
if max_pr == min_pr:
node_sizes = [min_size] * G.number_of_nodes()
else:
node_sizes = [
min_size + ((p - min_pr) / (max_pr - min_pr)) * (max_size - min_size)
for p in pagerank_values
]
else:
node_sizes = [min_size] * G.number_of_nodes()
# Lógica de Color (Monocromático)
try:
cmap_color = plt.colormaps.get_cmap('Blues_r')
except AttributeError:
cmap_color = plt.cm.get_cmap('Blues_r')
# Lógica de Grosor de Línea
edge_weights = [data['weight'] for u, v, data in G.edges(data=True)]
base_width = 1.0
max_extra_width = 6.0
scaled_widths = []
if edge_weights:
min_w = min(edge_weights)
max_w = max(edge_weights)
if max_w == min_w:
scaled_widths = [base_width] * len(edge_weights)
else:
scaled_widths = [
base_width + (((w - min_w) / (max_w - min_w)) * max_extra_width)
for w in edge_weights
]
else:
scaled_widths = [base_width] * len(edge_weights)
# Lógica de Etiquetas
custom_labels = {
node: f"{node.capitalize()}\n({data.get('occurrences', '?')})"
for node, data in G.nodes(data=True)
}
# Dibujar Nodos
nx.draw_networkx_nodes(
G, pos,
node_color=pagerank_values,
cmap=cmap_color,
node_size=node_sizes,
alpha=0.8,
edgecolors='black',
linewidths=1.5
)
# Dibujar Aristas
nx.draw_networkx_edges(
G, pos,
alpha=0.3,
width=scaled_widths,
edge_color='grey'
)
# Dibujar Etiquetas
nx.draw_networkx_labels(G, pos, labels=custom_labels, font_size=12, font_color='black', font_weight='bold')
plt.title(title, size=20)
plt.tight_layout()
plt.savefig(output_filename, dpi=300, bbox_inches='tight')
plt.close()
print(f"\nGráfico '{output_filename}' guardado con éxito! (Monocromático y grosor dinámico)")
## ----------------------------------------------------------------
## BLOQUE DE EJECUCIÓN PRINCIPAL (CON PASO DE EDICIÓN)
## ----------------------------------------------------------------
if __name__ == "__main__":
# --- Parámetros de Entrada ---
FILE_PATH = 'extractos.txt'
TOP_N_NODES = 20
MIN_EDGE_WEIGHT_VIZ = 5
GRAFICO_TITULO = "Análisis de Red (Monocromático)"
GRAFICO_OUTPUT_FILE = "analisis_red_monocromatica.png"
MAPEO_ETIQUETAS_FILE = 'mapeo_terminos.csv'
# --- 1. Flujo de trabajo estándar (hasta el filtrado) ---
print("Iniciando análisis...")
matriz_M = create_cooccurrence_matrix_from_file(FILE_PATH)
grafo_base = nx.from_pandas_adjacency(matriz_M)
grafo_com_metricas = calcular_e_associar_metricas(grafo_base, matriz_M)
grafo_final = filtrar_rede(grafo_com_metricas, top_n=TOP_N_NODES, min_edge_weight_for_viz=MIN_EDGE_WEIGHT_VIZ)
# --- 2. Exportar nodos para corrección de tildes ---
nodos_sin_tildes = list(grafo_final.nodes())
df_mapa = pd.DataFrame({
'original_sin_tilde': nodos_sin_tildes,
'corregido_con_tilde': nodos_sin_tildes
})
df_mapa.to_csv(MAPEO_ETIQUETAS_FILE, index=False, encoding='utf-8-sig')
# --- 3. Pausa para la edición manual ---
print("-" * 70)
print(f"ARCHIVO CREADO: '{MAPEO_ETIQUETAS_FILE}'")
print("Por favor, abre este archivo CSV (con Excel, Google Sheets, o un editor de texto).")
print("Modifica la columna 'corregido_con_tilde' para añadir las tildes necesarias.")
print("-" * 70)
input(">>> PRESIONA ENTER para continuar después de guardar tus cambios... ")
# --- 4. Importar mapa corregido y re-etiquetar ---
print("Leyendo el archivo de etiquetas corregido...")
try:
df_mapa_editado = pd.read_csv(MAPEO_ETIQUETAS_FILE, encoding='utf-8-sig')
except Exception as e:
print(f"Error leyendo el archivo {MAPEO_ETIQUETAS_FILE}: {e}")
print("Asegúrate de que el archivo esté guardado correctamente.")
# exit() # Comentado para que no detenga el script si se usa en un entorno no interactivo
mapa_de_etiquetas = pd.Series(
df_mapa_editado.corregido_con_tilde.values,
index=df_mapa_editado.original_sin_tilde
).to_dict()
grafo_etiquetado = nx.relabel_nodes(grafo_final, mapa_de_etiquetas, copy=True)
print("Nodos re-etiquetados con éxito.")
# --- 5. Visualización ---
visualizar_rede(
grafo_etiquetado,
GRAFICO_TITULO,
GRAFICO_OUTPUT_FILE
)